医咖会以后发送姚学甲进行分类logistic重回的SPSS讲义,不过很多难题未详尽阐释,比如,怎样校正:已连续常量与自表达式的logit切换值间存有差值;常量间无双重TNUMBERETDATE等。时常有合作伙伴问到这些难题,有鉴于此,我们对二进行分类logistic重回的讲义做了预览,期望能对我们略有协助。
某科学人类学家想介绍年纪、运动量、异性恋和最轻摄溶氧(VO2max)预估患中风的潜能,召募了100例科学研究第一类顺利完成最轻摄溶氧测试,注册登记年纪(age)、运动量(weight)和异性恋(gender),并评估结果科学研究第一类目前与否罹患中风(heart_disease)。
采用二进行分类Logistic数学模型前,需推论与否满足用户下列7项假定。
假定1:自表达式(故事情节)是二进行分类表达式。假定2:有最少1个常量,常量能是已连续表达式,也能是进行分类表达式。假定3:每一探测间互相分立。进行分类表达式(主要包括自表达式和常量)的进行分类要全面性且每一个进行分类间常量。假定4:最轻粒度明确要求为常量数量的15倍,但一些科学人类学家认为粒度应达到常量数量的50倍。假定5:已连续的常量与自表达式的logit切换值间存有差值。假定6:常量间无双重TNUMBERETDATE。假定7:没有显著的甲草点、资金成本点和强影响点。
假定1-4依赖于科学研究结构设计和统计正则表达式,本科学研究统计数据满足用户假定1-4。那么如果怎样检测假定5-7,并进行Logistics重回呢?
检测假定5:已连续的常量与自表达式的logit切换值间存有差值
已连续的常量与自表达式的logit切换值间与否存有差值,能通过多种不同方式检测。这里主要如是说Box-Tidwell方式,将要已连续常量与大自然对值的可视化项列入重回方程。
本科学研究中,已连续的常量主要包括年纪(age)、运动量(weight)、最轻摄溶氧(VO2max)。采用Box-Tidwell方式时,需要先排序age、weight和VO2max的大自然对值,并重新命名为ln_age、ln_weight、ln_VO2max。
(1) 排序已连续常量的大自然对值
以age为例,排序age的大自然对值ln_age的SPSS操作如下。
在主界面点击 Transform→Compute Variable,出现Compute Variable对话框中。在Target Variable框中输入将要生成大自然对值的表达式名称(如输入ln_age表示age的大自然对值)。
选择Function group菜单下的Arithmetic,选择Functions and special variables菜单下的Ln,双击Ln将该公式选入Numeric Expression框中,最后双击age将该表达式选入LN()公式中。点击OK生成新表达式ln_age(即age的大自然对值)。
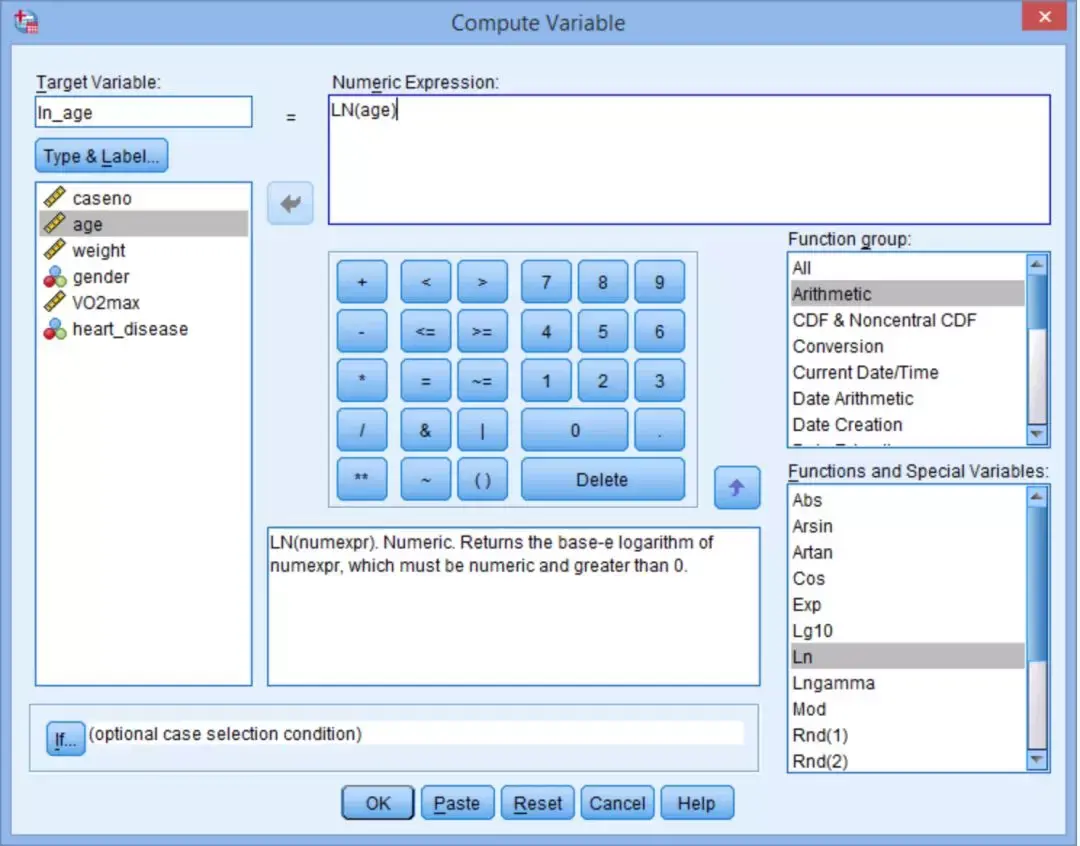
此时新表达式会同时出现在Variable View和Data View窗口中。在Data View窗口中,新生成的ln_age表达式如下图。
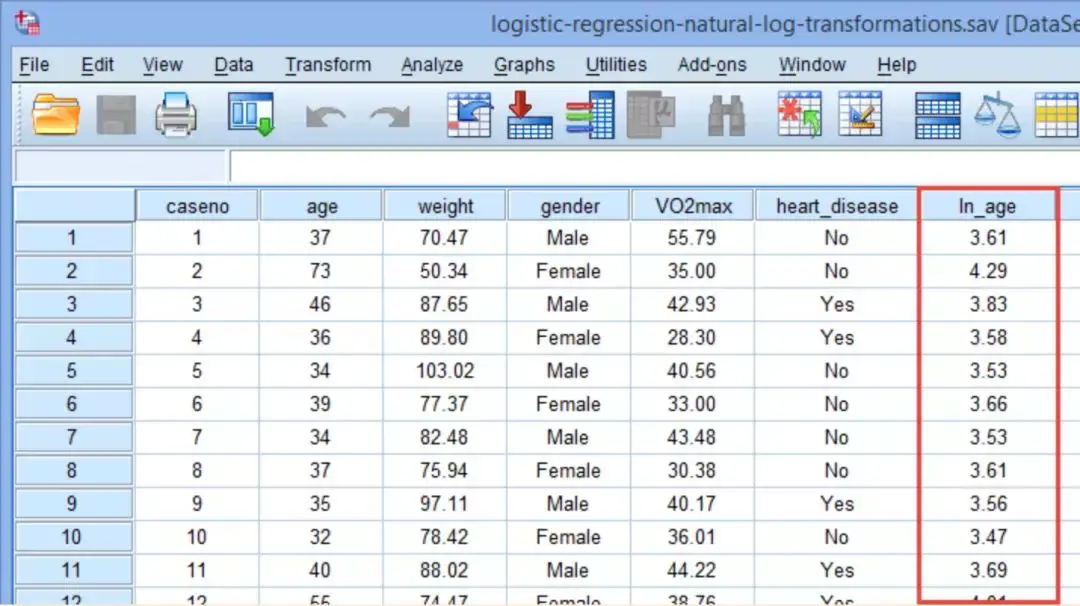
重复以上过程,将本科学研究中的所有已连续常量的大自然对值全部生成。在Data View中,新生成的ln_age,ln_weight,ln_VO2max表达式如下图。
(2) Box-Tidwell法
Box-Tidwell法检测已连续的常量与自表达式的logit切换值间与否存有差值的SPSS操作如下。
在主界面中点击 Analyze→Regression→Binary Logistic。在Logistic Regression对话框中将表达式heart_disease选入Dependent框中,将表达式age、weight、gender和VO2max选入Covariates框中。Methods选项选择默认值,即Enter。如果目前未选择Enter,应修改为Enter。
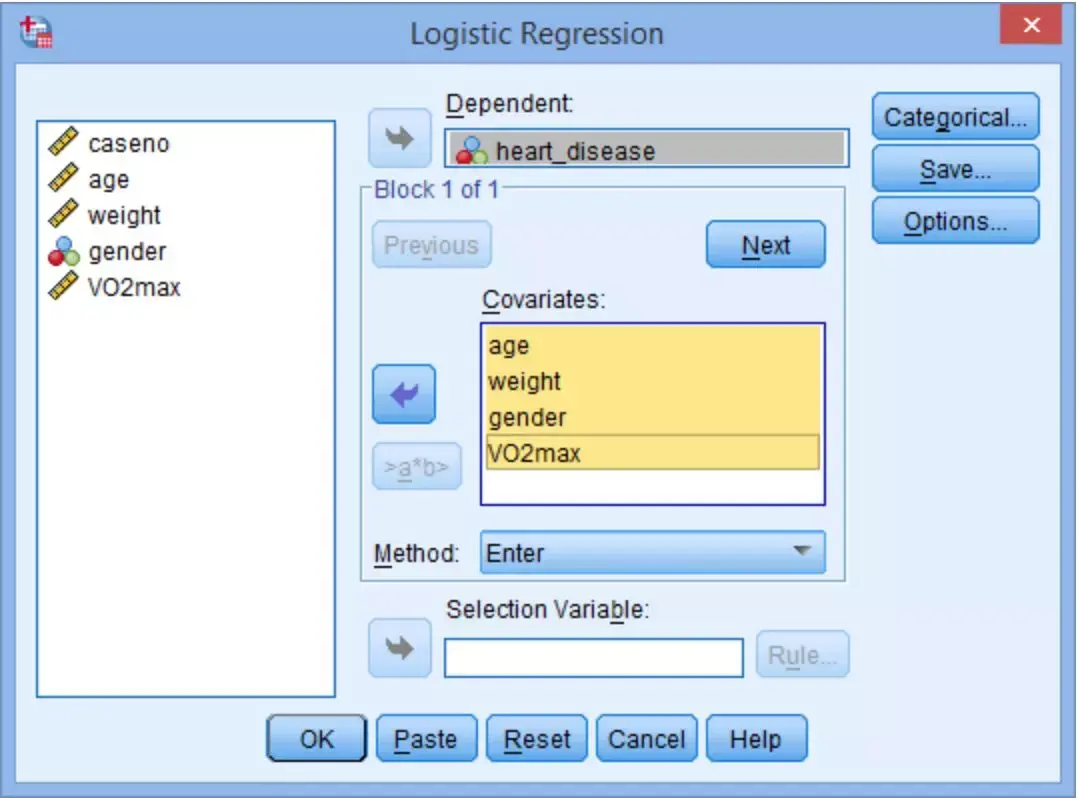
点击Categorical,在Logistic Regression:Define Categorical Variables对话框中,将gender选入Categorical Covariates框中。在Change Contrast区域,将Reference Category从Last改为First后,点击Change→Continue。
对于二进行分类表达式(如本科学研究的gender),也能不通过Categorical选项指定参照,SPSS将默认以赋值较低的表达式为参照。
Categorical选项可将多进行分类表达式(主要包括有序多进行分类和无序多进行分类)变换成哑表达式,指定某一进行分类为参照。比如,某科学研究中COPD是多进行分类表达式(分为无COPD病史、轻/中度、中度),如果指定无COPD病史的科学研究第一类为参照组,能分别比较轻/中度和重度组相对于参照组发生故事情节的风险。
Contrast右侧的下拉菜单中(该下拉菜单内的选项是几种与参照比较的方式),Indicator方式最常用,其比较方式为:第一类或最后一类为参照类,每一类与参照类比较。在Reference Category的右侧选择First,表示本科学研究以女性为对照组(赋值为0)。
回到Logistic Regression对话框后,可见gender已显示为gender(Cat)。进行分类表达式后显示(Cat)说明已正确定义进行分类表达式。
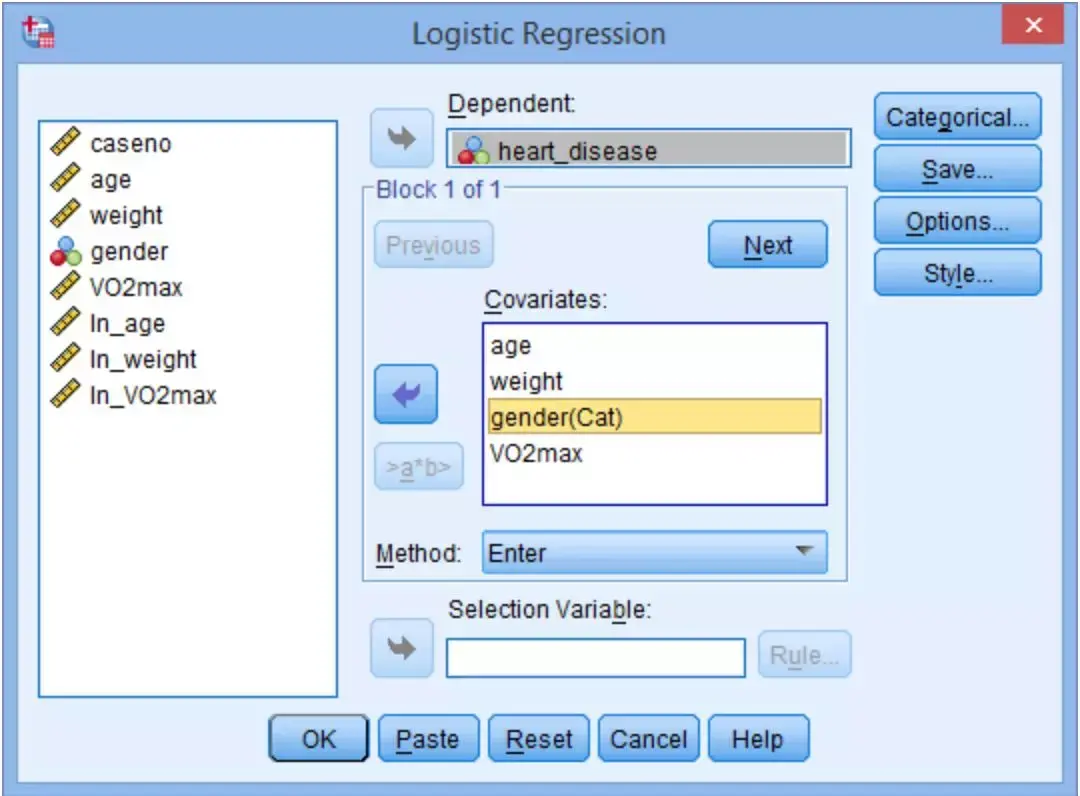
设置好进行分类常量后,开始生成可视化项。以age和ln_age为例,同时选中age和ln_age(采用Ctrl键+鼠标点击),点击>a*b>键,将ln_age*age可视化项选入Covariates框中。
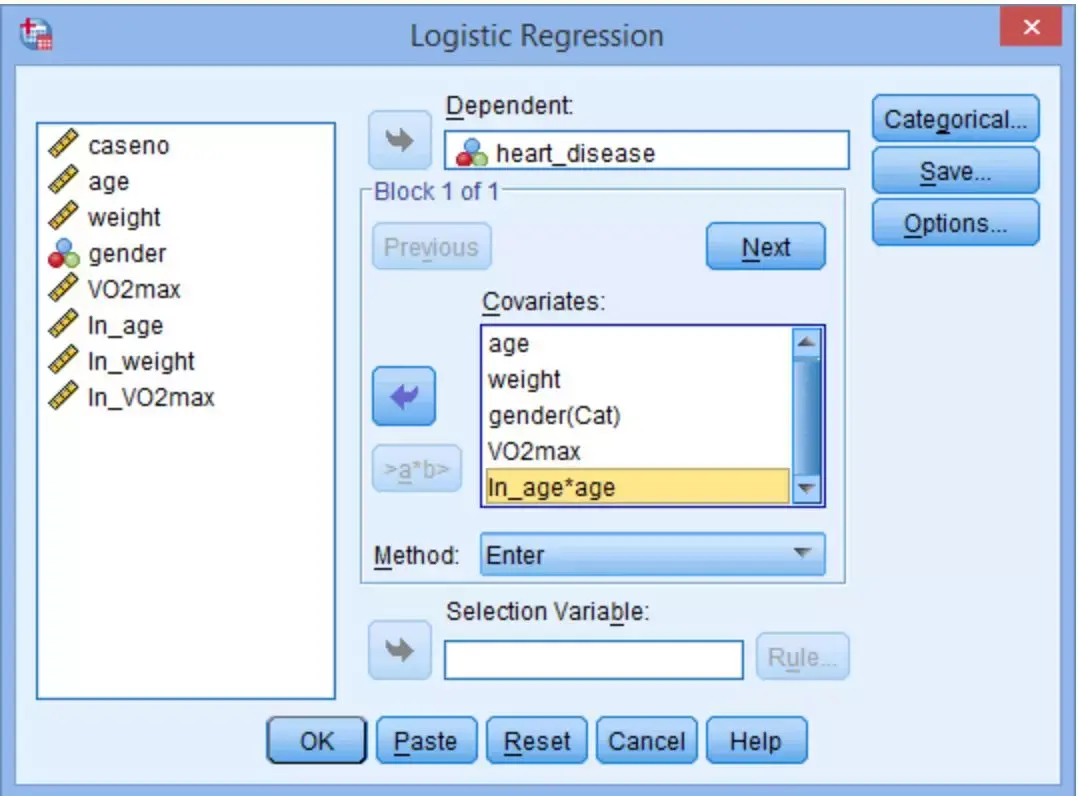
重复以上过程,将所有可视化项都选入Covariates框中,点击OK。

(3) 假定5的检测结果
查看Variables in the Equation表格中,有可视化作用的行及行内Sig值,本科学研究中为age by ln_age、ln_weight by weight和VO2max by ln_VO2max所在的行及行内Sig值。
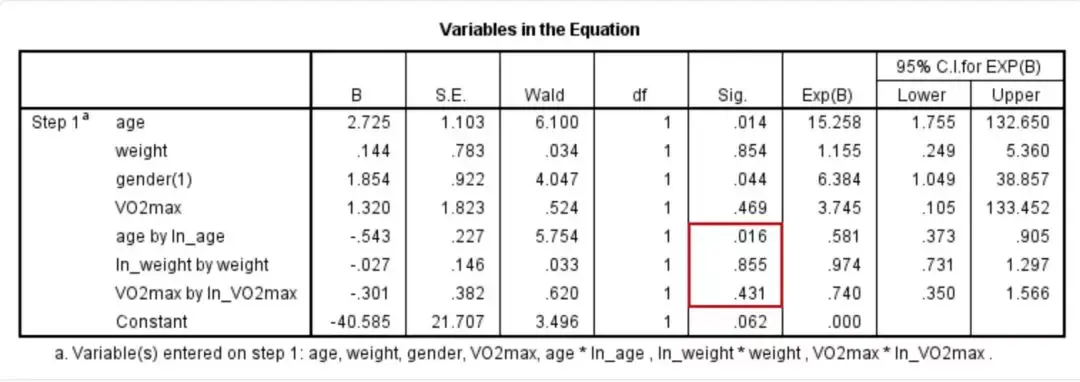
如果可视化作用有统计学意义(P<0.05),则说明对应的已连续常量与自表达式logit切换值间没有差值(即不符合假定5)。尽管解释重回结果时通常不进行双重校正,但在检测线性假定时建议对列入分析的所有项(主要包括截距项)进行Bonferroni法校正。
本科学研究中,共有8项列入数学模型分析,主要包括三个已连续常量age、weight、VO2max,进行分类常量gender,三个可视化作用项age*ln_age、ln_weight*weight、VO2max*ln_VO2max和截距项(Constant)。
因此本科学研究中,建议选择显著性水平应为α=0.00625(即0.05 ÷ 8)。根据该显著性水平,本科学研究所有可视化项的P值均高于0.00625,因此所有已连续常量与自表达式logit切换值间存有差值。
假定5检测完之后,有两种情况:① 所有已连续常量与自表达式的logit切换值间存有差值,则直接进行下一步;② 如果一个及以上已连续常量与自表达式的logit切换值间不存有差值,建议将该表达式切换为有序进行分类表达式。
(关于Box-Tidwell法,我们主要参考了外文的一些资料,小咖手上有两个PDF,有需要的合作伙伴,请在下方留言。)
检测假定6:常量间无双重TNUMBERETDATE
与线性重回一样,Logistic重回数学模型也需要检测常量间与否存有双重TNUMBERETDATE。常量间的简单相关或双重相关都会产生双重TNUMBERETDATE。
容忍度(Tolerance)或方差膨胀因子(VIF)能用来诊断常量间的双重TNUMBERETDATE。遗憾的是,SPSS的Binary Logistic模块并不能提供容忍度或方差膨胀因子,但是我们能通过线性重回来获得。
由于我们关心的是常量间的亲密关系,因此容忍度或方差膨胀因子与数学模型中自表达式的函数形式无关。也就是说,我们能将Logistic重回的自表达式(二进行分类表达式)、常量(二进行分类、多进行分类或已连续表达式)直接带入线性重回数学模型,从而获得容忍度或方差膨胀因子。
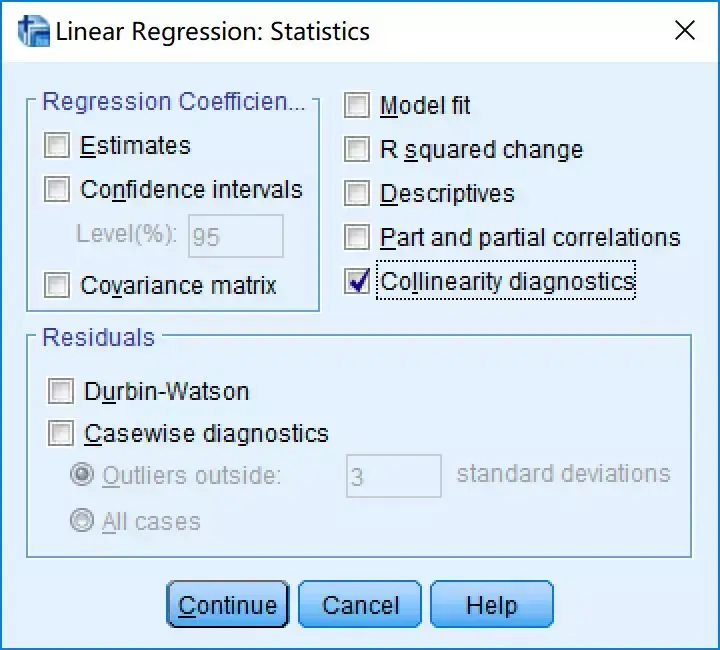
在主界面点击Analyze→Regression→Linear,将heart_disease选入Dependent,将age、weight、gender和VO2max选入Independent(s)。
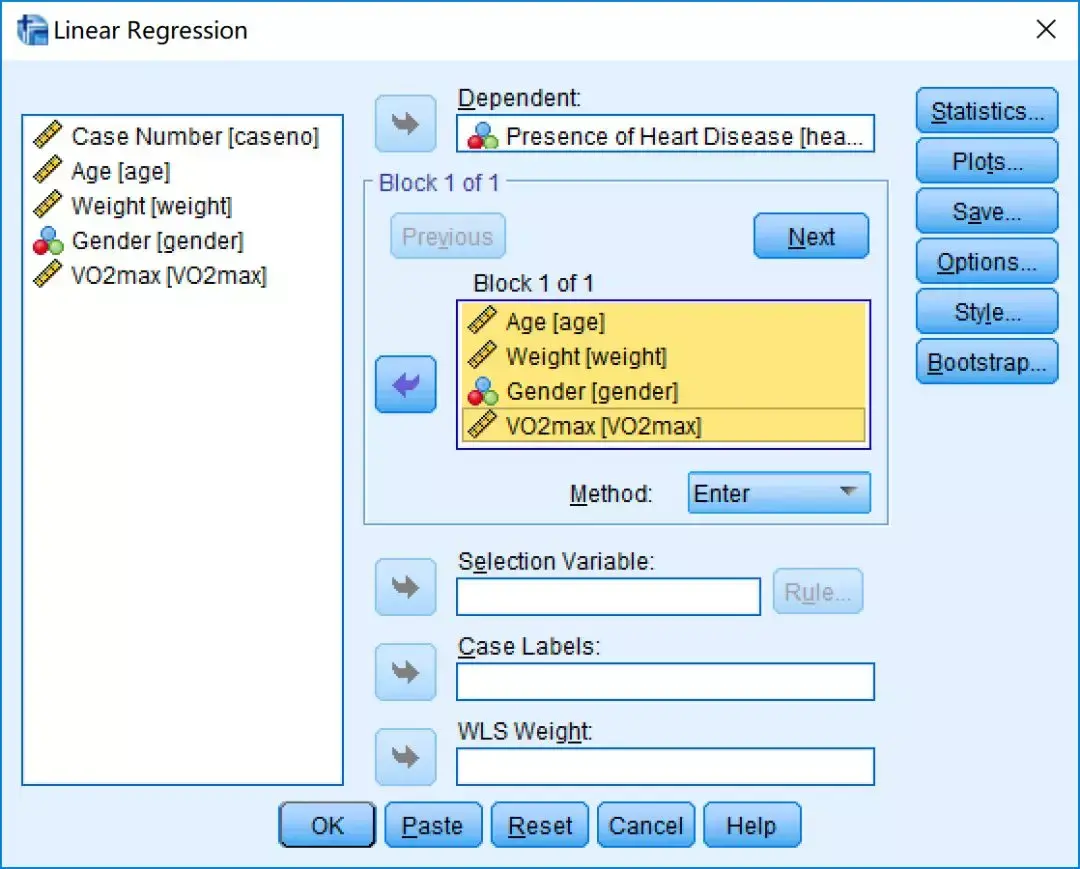
点击Statistics,出现Linear Regression:Statistics对话框,点击Collinearity diagnostics→Continue→OK。
结果如下图:
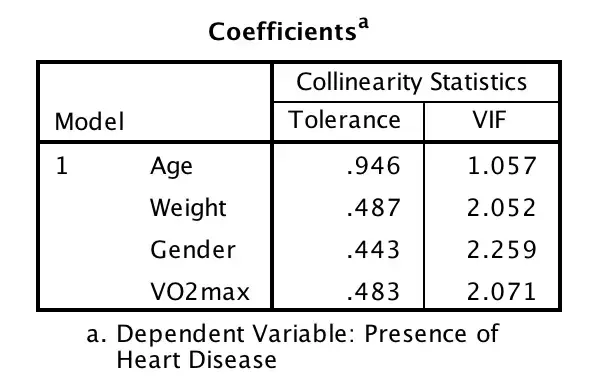
如果容忍度(Tolerance)小于0.1或方差膨胀因子(VIF)大于10,则表示有TNUMBERETDATE存有。本例中,容忍度均远大于0.1,方差膨胀因子均小于10,所以不存有双重TNUMBERETDATE。如果统计数据存有双重TNUMBERETDATE,则需要用复杂的方式进行处理,其中最简单的方式是剔除引起TNUMBERETDATE的因素之一,剔除哪一个因素能基于理论依据。
检测假定7:没有显著的甲草点、资金成本点和强影响点
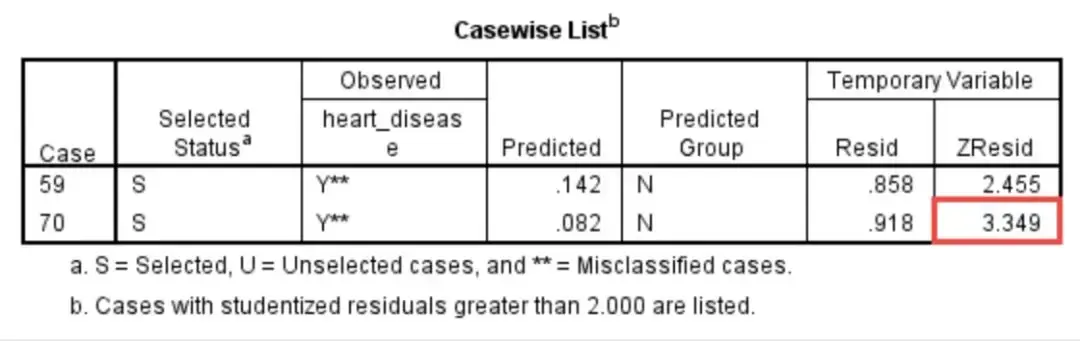
该假定的SPSS操作可见后面的Logistic 重回部分,此处仅展示怎样解读结果。结果中Casewise List表格显示学生化残差大于2倍标准差的探测。学生化残差大于2.5倍标准差的探测需要科学人类学家进一步观察决定这些探测与否是甲草点,如有必要甚至能从分析中剔除这些探测。
本例中,第70个探测(Case Number)的学生化残差为3.349,符合上述推论甲草点的标准。
需要注意的是:
① 如果所有探测的学生化残差小于2倍标准差,SPSS不会输出Casewise List表格。如果已经剔除甲草点,则第一次分析得到的Casewise Diagnostics表格不会再显示。
② 探测数(Case Number)指SPSS系统内自动编码(Data View窗口中最左侧蓝色一列中的编码),而非科学人类学家赋值的编码。
③ 科学人类学家需要查看该探测为甲草点的原因,决定与否删除该探测并报告。本科学研究考虑不删除该探测,并在结果中报告列入分析的探测中有一项探测的学生化残差为3.349。
Logistic 重回
在主界面点击Analyze→Regression→Binary Logistic,在Logistic Regression对话框中,将heart_disease选入Dependent,将age、weight、gender和VO2max选入Covariates。并按照前述操作,通过Categorical将gender变换为哑表达式。
注意:如果是按本文中指导的步骤依次进行的分析,此时Logistic Regression对话框下为自表达式heart_disease,Covariates框中为4个常量age、weight、gender(Cat)、VO2max和3个可视化项ln_age*age、ln_weight*weight、ln_VO2max* VO2max。
此时仅需要将可视化项ln_age*age、ln_weight*weight、ln_VO2max* VO2max从Covariates框中删除即可。
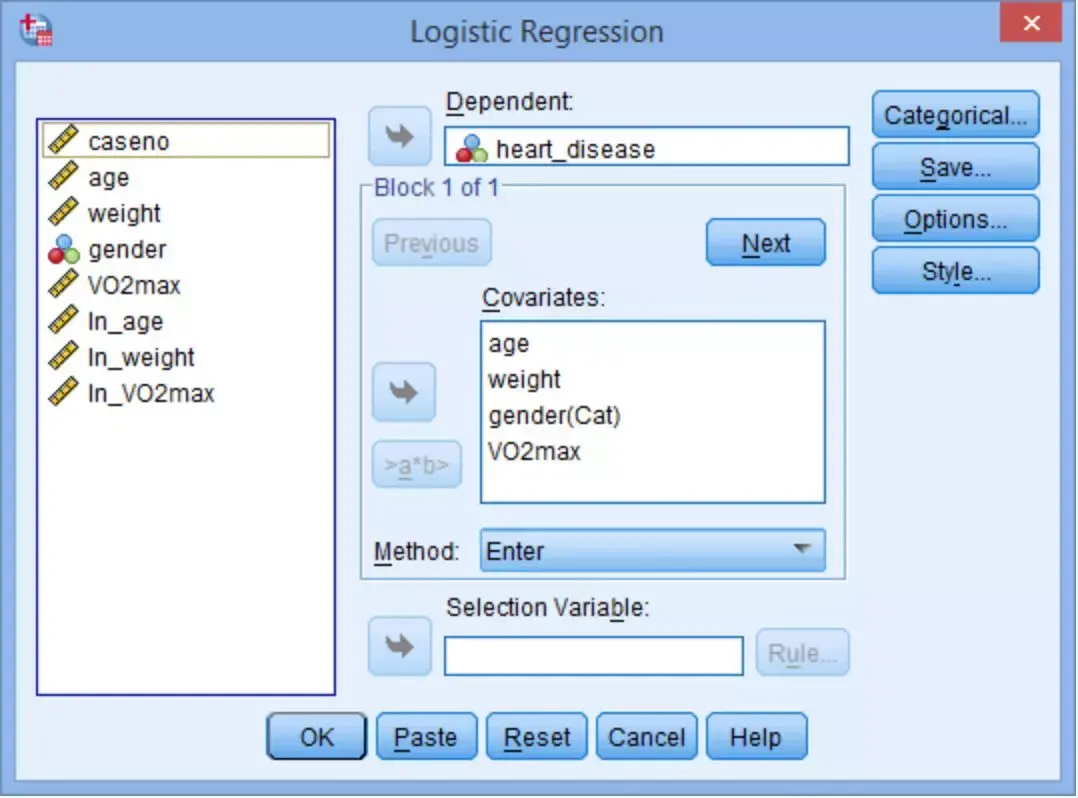
对于常量筛选的方式(Method对话框),SPSS提供了7种选择,采用各种方式的结果略有不同,读者可互相印证。各种方式间的差别在于表达式筛选方式不同,其中Forward: LR法(基于最轻似然估计的向前逐步重回法)的结果相对可靠,但最终数学模型的选择还需要获得专业理论的支持。本文以Enter法为例进行展示(其它方式得到的结果,解释方式一样)。
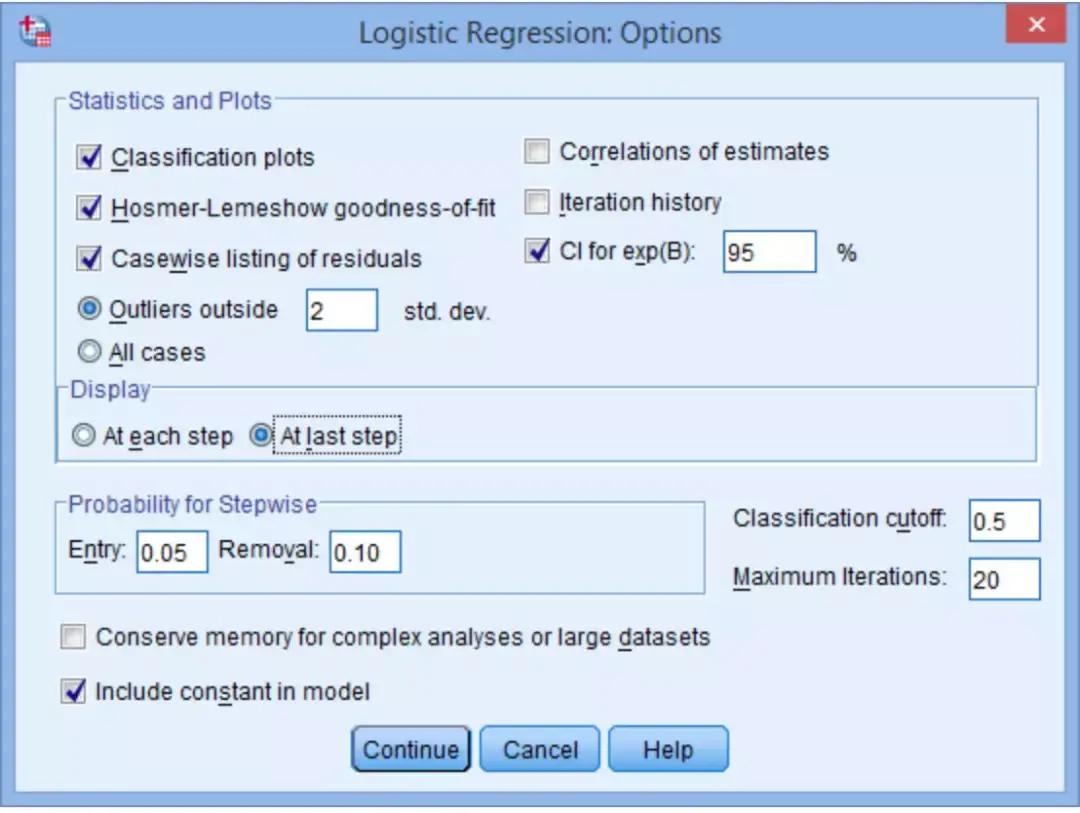
点击Options,在Logistic Regression:Options对话框中,选中Classification plots,Hosmer-Lemeshow goodness-of-fit,Casewise listing of residuals和CI for exp(B)这4个选项。在Display区域,选中At last step选项。点击Continue→OK。
1. 检查表达式和统计数据
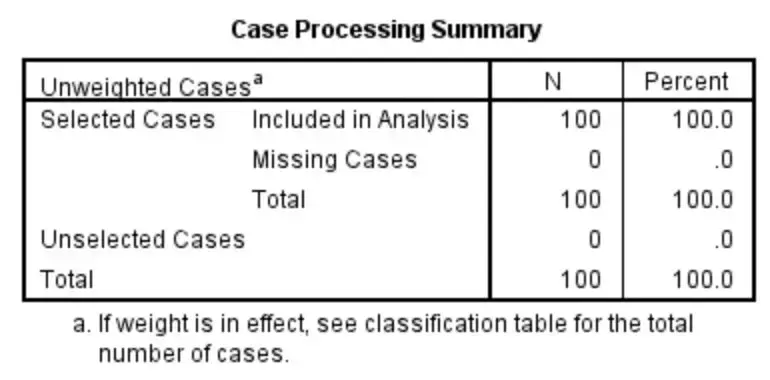
首先检查与否存有缺失探测,列入分析的探测数与否和统计数据库中探测数一致。Case Processing Summary表格如下图。
确认自表达式的编码与否正确。Dependent Variable Encoding表格如下图。

观察进行分类常量与否存有某一类探测数过少的情况,如果某项进行分类较少,可能不利于对顶角Logistic重回分析。本科学研究中,定义的进行分类常量只有gender,因此Categorical Variables Codings表格只给出了gender的信息。

2. 基本分析
此部分结果的标题为Block 0:Beginning Block,指的是所有常量不列入数学模型、只主要包括常数项时的结果。此部分能跳过。
3. Logistic重回
此部分结果的标题为Block 1:Method=Enter(Enter指前述SPSS操作部分所述的常量筛选方式)。
(1) 数学模型整体评价
Omnibus Tests of Model Coefficients是数学模型系数的综合检测。其中Model一行输出了Logistic重回数学模型中所有参数与否均为0的似然比检测结果。P<0.05表示本次拟合的数学模型中,列入的表达式中,最少有一个表达式的OR值有统计学意义,即数学模型总体有意义。
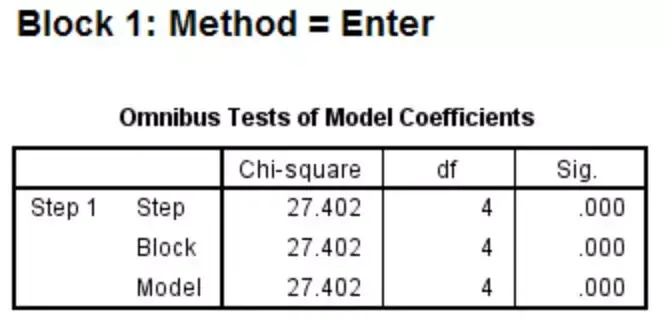
Hosmer and Lemeshow Test是检测数学模型的拟合优度。当P值不小于检测水准时(即P>0.05),认为当前统计数据中的信息已经被充分提取,数学模型拟合优度较高。
Model Summary表格中,提供了自表达式的变异能够被拟合的数学模型解释的比例。该表格包含Cox & Snell R Square和Nagelkerke R Square,这两种R2有时被称为伪R2,在Logistic重回中意义不大(与线性重回中的不同),能不予关注。
(2) 数学模型预估潜能
拟合Logistic重回数学模型后,对于每一个常量组合,均能得到故事情节事件(本例中为患中风)发生的概率。如果事件发生的概率大于或等于0.5,Logistic重回推论为事件发生(患中风);如果可能性小于0.5,则推论为事件未发生(未患中风)。因此,与真实情况相比,就能评价Logistic重回数学模型的预估效果。
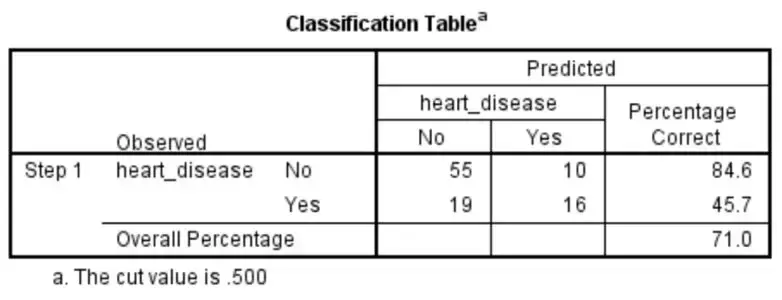
Logistic重回数学模型能够将71.0%的探测正确进行分类(Overall Percentage一行),该指标常被称作percentage accuracy in classification(正确进行分类百分比),即诊断测试中的一致率。
预估为是的探测数占实际为是的探测数的比例即灵敏度。本科学研究中,45.7%罹患中风的科学研究第一类被数学模型预估罹患中风。预估为否的探测数占实际为否的探测数的比例即特异度。本科学研究中,84.6%未患中风的科学研究第一类被数学模型预估未患中风。
同理,还能排序得到阳性预估值(61.5%)和阴性预估值(74.3%)。
(3) 方程中的常量
由于本次统计过程中筛选表达式的方式是Enter法,因此所有常量均进入了数学模型,Variables in the Equation表格中也列出了所有常量及其参数。其中Sig.一列表示相应表达式在数学模型中的P值,Exp (B)和95% CI for EXP (B)表示相应表达式的OR值和其95%可信区间。
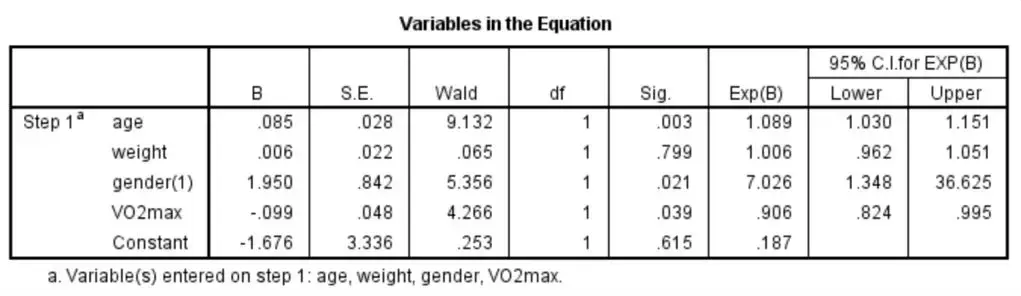
结果显示,age(P=0.003),gender(P=0.021)和VO2max(P=0.039)有统计学意义,但weight(P=0.799)没有统计学意义。
对于进行分类表达式,OR值的含义为:相对于赋值较低的科学研究第一类(gender赋值为0的为女性),赋值较高的科学研究第一类(男性)患中风的风险是多少(7.026倍)。对于已连续表达式,OR值的含义为:常量每增加一个单位(年纪每增加1岁),发生故事情节的风险增加的倍数(1.089倍)。
本科学研究采用二进行分类Logistic重回评估结果年纪、运动量、异性恋和最轻摄溶氧对科学研究第一类患中风的影响。采用Box-Tidwell方式检测已连续常量与自表达式logit切换值间与否为线性。线性检测数学模型时共列入8项,Bonferroni校正后显著性水平为0.00625。线性检测结果得到所有已连续常量与自表达式logit切换值间存有差值。一个探测的学生化残差为标准差的3.349倍,但保留在分析中。
最终,得到的Logistic数学模型具有统计学意义,χ2=27.402,P<0.0005。该数学模型能够正确进行分类71.0%的科学研究第一类。数学模型的敏感度为45.7%,特异度为84.6%,阳性预估值为61.5%,阴性预估值为74.3%。
数学模型列入的五个常量中,年纪、异性恋和最轻摄溶氧有统计学意义。男性患中风的风险是女性的7.026倍。年纪每增加1岁,患中风的风险增加8.9%。最轻摄溶氧每增加一个单位,患中风的风险降低9.4%。
在进行二进行分类Logistic重回(主要包括其它Logistic重回)分析前,如果样本不多而表达式较多,建议先通过单表达式分析(t检测、卡方检测等)考察所有常量与自表达式间的亲密关系,筛掉一些可能无意义的表达式,再进行多因素分析,这样能保证结果更加可靠。
即使样本足够大,也不建议直接把所有的表达式放入方程直接分析,一定要先弄清楚各个表达式间的互相亲密关系,确定常量进入方程的形式,这样才能有效的进行分析。
经过单因素分析后,应当考虑如果将哪些常量列入Logistic重回数学模型。一般情况下,建议列入的表达式有:1)单因素分析差异有统计学意义的表达式(此时,最好将P值放宽一些,比如0.1或0.15等,避免漏掉一些重要因素);2)单因素分析时,没有发现差异有统计学意义,但是临床上认为与自表达式亲密关系密切的常量。
此外,对于已连续表达式,如果仅仅是为了调整该表达式带来的混杂(不关心该表达式的OR值),则能直接将改表达式列入Logistic重回数学模型;如果关心该表达式对自表达式的影响程度(关心该表达式的OR值),一般不直接将该已连续表达式列入数学模型,而是建议将已连续表达式转化为有序多进行分类表达式后列入数学模型。
这是因为,在Logistic重回中直接列入已连续表达式,那么对于该表达式的OR值的意义为:该表达式每升高一个单位,发生故事情节事件的风险变化(比如年纪每增加1岁,患中风的风险增加1.089倍)。这种解释在临床上大多数是没有意义的。
(如果想采用文中统计数据进行练习,请采用电脑打开下列网址:
点击左侧统计数据下载免费下载原始统计数据)

发表评论