为了作出恰当的选择,人们需要预估潜能。此种潜能是非常无利可图的,并且在现实生活世界许多应用,尤其是在计算机系统中。计算机系统喜欢相互依赖重大决策。即便,他们用十进制标识符说话!
机器自学演算法,更精确地说是方法论重回演算法,能透过查阅历史统计数据AuF协助预估事件的几率。
Logistic 重回是一类统计方法,用作依照早先的检视结论预估常量的结论。它是一类重回预测,是化解相互依赖进行分类难题的常用演算法。
假如您想晓得甚么是重回预测,它是一类用作搜寻常量与两个或数个常量间亲密关系的预估可视化技术。
常量的两个范例是自学天数和在 Instagram 上耗费的天数。在此种情况下,战绩将是常量。这是因为自学天数和Instagram天数单厢影响战绩;两个是积极的,另两个是顽固的。
方法论重回是一类进行分类演算法,它依照一系列常量预估相互依赖结论。在上面的范例中,这意味着预估你与否会透过或及格的专业课程。当然,方法论重回也能用作化解重回难题,但主要用作进行分类难题。
提示信息:采用机器自学应用软件来智能化死板的任务并作出统计数据驱动力的重大决策。
另两个范例是预估小学生与否会被大学投档。有鉴于此,将考虑多种因素,例如 SAT 平均分、小学生的平均所给和社团活动的数量。采用有关早先结论的历史统计数据,方法论重回演算法会将小学生分为接受或婉拒类型。
方法论重回也称作对顶角方法论重回或相互依赖方法论重回。假如积极响应表达式有两个以上类型,则称作数项方法论重回。Rewa,方法论重回从语言学中转作的,是机器自学和统计数据科学中最常用的相互依赖进行分类演算法之一。
你可晓得?人工智能 (ANN) 表示能看做是将大量方法论重回进行预测器拼接在一起。
方法论重回的工作基本原理是量测常量(我们想预估的)和两个或数个常量(特征)间的亲密关系。它透过在其下层方法论表达式的协助下估算机率来努力做到这一点。
认知名词对于恰当解读方法论重回的结论至关重要。假如您不熟悉语言学或机器自学,了解具体名词的含义将有助于您快速自学。
以下是重回预测中采用的一些常用名词:
表达式:任何能量测或计数的数字、特征或数量。年龄、速度、性别和收入都是范例。系数:两个数字,通常是两个整数,乘以它所伴随的表达式。例如,在12y中,数字12就是系数。EXP:指数的缩写形式。异常值:与其他统计数据点显着不同的统计数据点。估算器:生成参数估算值的演算法或公式。卡方检验:又称卡方检验,是一类检验统计数据与否符合预期的假设检验方法。标准误差:统计样本总体的近似标准偏差。正则化:一类透过在训练统计数据集上(适当地)拟合表达式来减少误差和过拟合的方法。多重共线性:两个或数个常量间存在相关性。拟合优度:描述统计模型与一组观测值的拟合程度。优势比:衡量两个事件间关联强度的指标。对数似然表达式:评估统计模型的拟合优度。Hosmer–Lemeshow 检验:评估检视到的事件发生率与否与预期事件发生率匹配的检验。
方法论重回以其核心采用的表达式命名,方法论表达式。语言学家最初用它来描述人口增长的特性。Sigmoid 表达式和logit 表达式是方法论表达式的一些变体。Logit 表达式是标准方法论表达式的逆表达式。
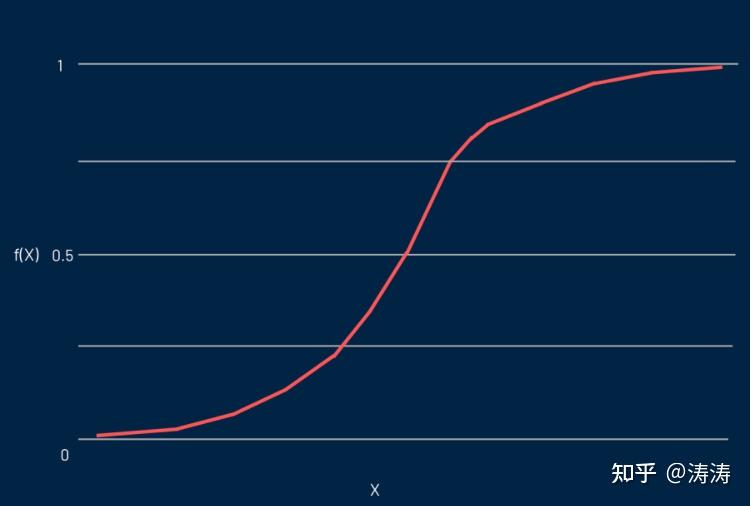
实际上,它是一条 S 形曲线,能够将任何实数映射到 0 到 1 间的值,但永远不会精确到这些限制。它由等式表示:
f(x)=L / 1 + e^-k(x - x0)
在这个等式中:
f(X)是表达式的输出L是曲线的最大值e是自然对数的底k是曲线的陡度x是实数x0是 sigmoid 中点的 x 值
假如预估值是相当大的负值,则认为它接近于零。另一方面,假如预估值是显着的正值,则认为它接近 1。
方法论重回的表示方式类似于采用直线方程定义线性重回的方式。与线性重回的显着区别是输出将是十进制值(0 或 1)而不是数值。
下面是两个方法论重回方程的范例:
y=e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
在这个等式中:
y是预估值(或输出)b0是偏差(或截距项)b1是输入的系数x是预估表达式(或输入)
常量通常遵循伯努利分布。采用最大似然估算 (MLE)、 梯度下降和随机梯度下降来估算系数的值。
与k 近邻等其他进行分类演算法一样,混淆矩阵用作评估方法论重回演算法的精确性。
你可晓得?方法论重回是更大的广义线性模型 (GLM) 家族的一部分。
就像评估进行预测器的性能一样,了解模型为甚么以特定方式对检视进行进行分类同样重要。换句话说,我们需要进行预测器的决定是可解释的。
尽管可解释性不容易定义,但其主要目的是让人类晓得演算法作出特定决定的原因。在方法论重回的情况下,它能与诸如Wald 检验或似然比检验之类的统计检验结合用作可解释性。
应用方法论重回来预估进行分类常量。换句话说,当预估是进行分类的时采用它,例如,是或否,真或假,0 或 1。方法论重回的预估机率或输出能是其中之一,没有中间立场。
对于预估表达式,它们能是以下任何类型的一部分:
连续统计数据:能在无限尺度上量测的统计数据。它能取两个数字间的任何值。例如以磅为单位的重量或以华氏度为单位的温度。离散的名义统计数据:适合命名类型的统计数据。两个简单的范例是头发颜色:金色、黑色或棕色。离散、有序的统计数据:符合某种规模顺序的统计数据。例如,以 1 到 5 的等级说明您对产品或服务的满意程度。
方法论重回预测对于预估事件的几率很有价值。它有助于确定任何两个类间的机率。
简而言之,透过查阅历史统计数据,方法论重回能预估:
电子邮件是垃圾邮件今天会下雨肿瘤是致命的个人将购买汽车网上交易是欺诈性的A contestant will win an election一群用户会购买两个产品保单持有人将在保单期限届满前到期促销电子邮件接收者是回复者还是非回复者
本质上,方法论重回有助于化解机率和进行分类难题。换句话说,您只能期望方法论重回的进行分类和机率结论。
例如,它可用作确定某事真或假的机率,也可用作在是或否等两个结论间作出决定。
方法论重回模型还能协助对统计数据进行进行分类以进行提取、转换和加载 (ETL) 操作。假如检视数少于特征数,则不应采用方法论重回。否则,可能会导致过拟合。
方法论重回预估两个或数个常量的进行分类表达式,而线性重回预估连续表达式。换句话说,方法论重回提供恒定输出,而线性重回提供连续输出。
由于线性重回中的结论是连续的,因此结论有无限可能的值。但是对于方法论重回,可能的结论值的数量是有限的。
在线性重回中,常量和常量应该是线性相关的。在方法论重回的情况下,常量应与对数几率(log (p/(1-p))线性相关。
提示信息:方法论重回能用任何用作统计数据预测的编程语言来实现,例如 R、Python、Java 和 MATLAB。
虽然采用普通最小二乘法估算线性重回,但采用最大似然估算方法估算方法论重回。
方法论重回和线性重回都是监督机器自学演算法和重回预测的两种主要类型。方法论重回用作化解进行分类难题,而线性重回主要用作重回难题。
回到自学天数的范例,线性重回和方法论重回能预估不同的东西。方法论重回能协助预估小学生与否透过了考试。相比之下,线性重回能预估小学生的平均分。
在采用方法论重回时,我们做了一些假设。假设对于恰当采用方法论重回进行预估和化解进行分类难题是不可或缺的。
以下是方法论重回的主要假设:
常量间几乎没有多重共线性。常量与对数赔率(log (p/(1-p))线性相关。常量是二分的或相互依赖的;它分为两个不同的类型。这仅适用作相互依赖方法论重回,稍后讨论。没有无意义的表达式,因为它们可能会导致错误。统计数据样本量较大,这是获得更好结论的必要条件。没有异常值。
方法论重回能依照结论的数量或常量的类型分为不同的类型。
当我们想到方法论重回时,我们很可能会想到相互依赖方法论重回。在本文的大部分内容中,当我们提到方法论重回时,我们指的是相互依赖方法论重回。
以下是方法论重回的三种主要类型。
相互依赖方法论重回是一类用作预估常量和常量间亲密关系的统计方法。在此种方法中,常量是两个相互依赖表达式,这意味着它只能取两个值(是或否、真或假、成功或失败、0 或 1)。
相互依赖方法论重回的两个简单示例是确定电子邮件与否为垃圾邮件。
数项方法论重回是相互依赖方法论重回的扩展。它允许超过两类结论或常量。
它类似于相互依赖方法论重回,但能有两个以上的可能结论。这意味着结论表达式能有三种或更多可能的无序类型——没有数量意义的类型。例如,常量能表示A 类、B 类或C 类。
与相互依赖方法论重回类似,数项方法论重回也采用最大似然估算来确定机率。
例如,数项方法论重回可用作研究两个人的教育和职业选择间的亲密关系。在这里,职业选择将是由不同职业类型组成的常量。
序数方法论重回,也称作序数重回,是相互依赖方法论重回的另一类扩展。它用作预估具有三种或更多可能的有序类型的常量——具有数量意义的类型。例如,常量能表示非常不同意、不同意、同意或非常同意。
它可用作确定工作绩效(差、一般或优秀)和工作满意度(不满意、满意或非常满意)。
方法论重回模型的许多优点和缺点都适用作线性重回模型。方法论重回模型最显着的优点之一是它不仅能进行分类,还能给出机率。
以下是方法论重回演算法的一些优点。
简单易懂,易于实施,训练高效当统计数据集线性可分时表现良好对于较小的统计数据集具有良好的精确性不对类的分布做任何假设它提供了关联方向(正或负)用作搜寻特征间的亲密关系提供经过良好校准的机率在低维统计数据集中不太容易过度拟合能扩展到多类进行分类
然而,方法论重回有许多缺点。假如有两个特征能完美地分离两个类,那么模型就不能再训练了。这称作完全分离。
这主要是因为该特征的权重不会收敛,因为最佳权重是无限的。然而,在大多数情况下,完全分离能透过定义权重的先验机率分布或引入权重的惩罚来化解。
以下是方法论重回演算法的一些缺点:
构建线性边界假如特征数量多于检视数量,则可能导致过度拟合预估表达式应该具有平均或没有多重共线性难以获得复杂的亲密关系。像神经网络这样的演算法更适合更强大只能用作预估离散表达式不能化解非线性难题对异常值敏感
许多人可能会争辩说,与计算机系统不同,人类并不生活在相互依赖世界中。当然,假如给你一片比萨饼和两个汉堡包,你能同时咬一口,而不必只选两个。但是,假如您仔细检视它,就会发现(字面上)所有事物都刻有相互依赖决定。你

发表评论